DynamicLabels
Supporting Informed Construction of Machine Learning Label Sets with Crowd Feedback



Yeon Su Park
KAIST

Jinyeong Yim
Yeon Su Park
KAIST
Jinyeong Yim
Label set construction—deciding on a group of distinct labels—is an essential stage in building a supervised machine learning (ML) application, as a badly designed label set negatively affects subsequent stages, such as training dataset construction, model training, and model deployment. Despite its significance, it is challenging for ML practitioners to come up with a well-defined label set, especially when no external references are available. Through our formative study (n=8), we observed that even with the help of external references or domain experts, ML practitioners still need to go through multiple iterations to gradually improve the label set. In this process, there exist challenges in collecting helpful feedback and utilizing it to make optimal refinement decisions. To support informed refinement, we present DynamicLabels, a system that aims to support a more informed label set-building process with crowd feedback. Crowd workers provide annotations and label suggestions to the ML practitioner’s label set, and the ML practitioner can review the feedback through multi-aspect analysis and refine the label set with crowd-made labels. Through a within-subjects study (n=16) using two datasets, we found that DynamicLabels enables better understanding and exploration of the collected feedback and supports a more structured and flexible refinement process. The crowd feedback helped ML practitioners explore diverse perspectives, spot current weaknesses, and shop from crowd-generated labels. Metrics and label suggestions in DynamicLabels helped in obtaining a high-level overview of the feedback, gaining assurance, and spotting surfacing conflicts and edge cases that could have been overlooked.
 Figure 1: Label set refinement workflow using DynamicLabels.
Figure 1: Label set refinement workflow using DynamicLabels.
DynamicLabels is a system that aims to support ML practitioners’ label set construction. DynamicLabels supports iterative refinement of the label set through two separate interfaces: the feedback collection interface and the label set refinement interface. The former is provided to the crowd to collect annotations and label suggestions on the ML practitioner-built label set, and the latter is provided to the ML practitioners for refinement with multiple analyses of crowd feedback.
 Figure 2: Phase 1 of the feedback collection interface.
Figure 2: Phase 1 of the feedback collection interface.
Crowd workers start from the Phase 1 task: creating their own label set (Fig. 2). They are first asked to take a look at 30 assigned images (Fig. 2-b) and come up with a set of labels (Fig. 2-a). Then, they are instructed to use the labels to make annotations (Fig. 2-c).
 Figure 3: Phase 2 of the feedback collection interface.
Figure 3: Phase 2 of the feedback collection interface.
Crowd workers then proceed to the next phase and use the ML practitioner-built label set to annotate the same 30 images (Fig. 3, b->c). In addition to the ML practitioner-built label set (Fig. 3-a), the workers are provided with an additional others label to annotate images that do not fit into the provided label set to spot edge cases. For each image labeled others, the workers are asked to provide a brief reason (Fig. 3-d) to justify their choice.
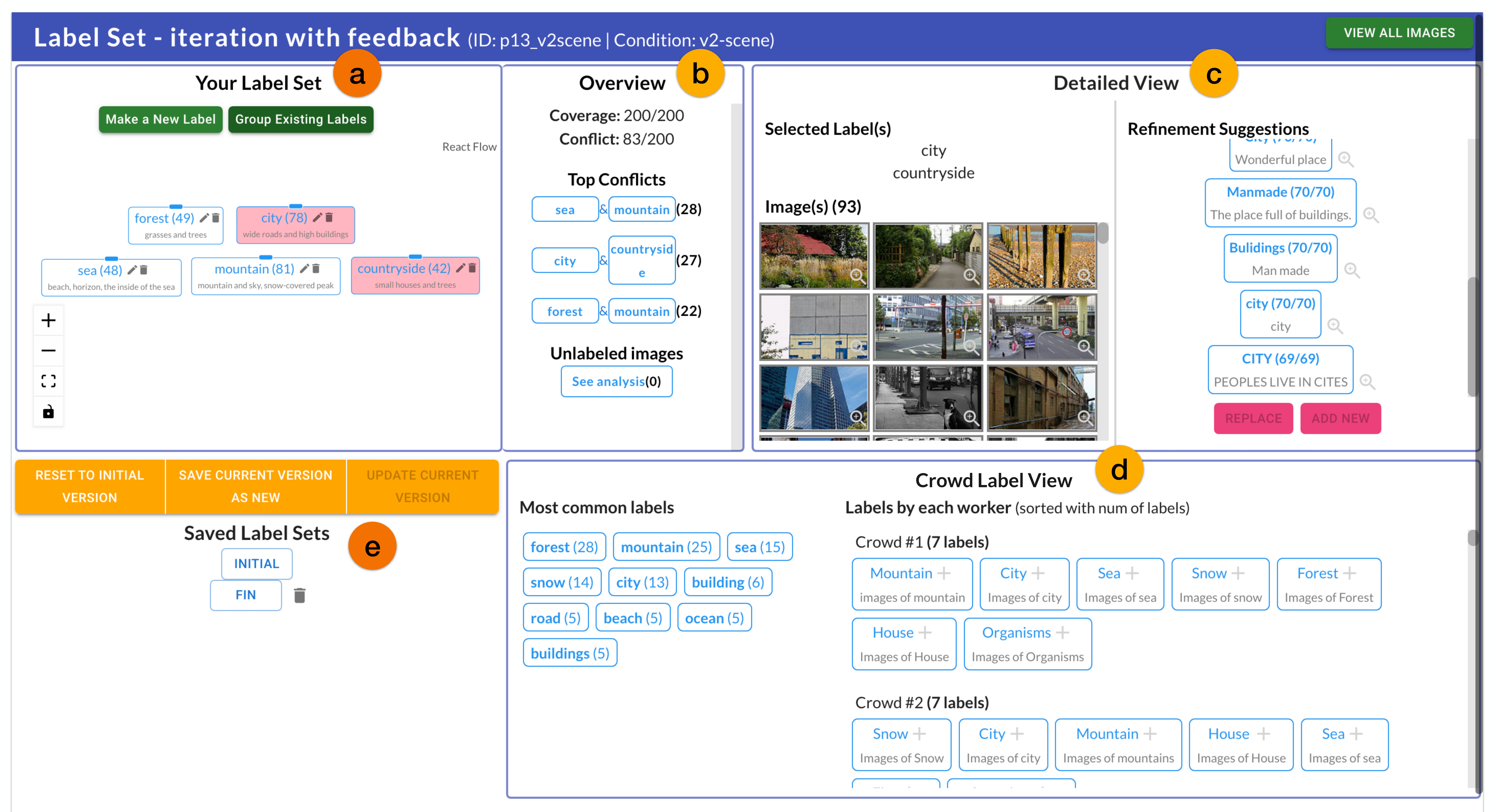 Figure 4: Overview of the label set refinement interface.
Figure 4: Overview of the label set refinement interface.
When the ML practitioner enters the label set refinement interface, they can find their initial label set on the top left, under “Your label set”. Right next to it is an overview (Fig. 4-b) that shows a summary created with the crowd feedback. Right next to it is an overview (Fig. 4-b) that shows a summary created with the crowd feedback. For the ML practitioner to understand the collected annotation in detail, they can select label(s), top conflicts, or unlabeled images to see a detailed view (Fig. 4-c). On the bottom right, the ML practitioner can explore refinement options, through an analysis of the crowd-made labels through the crowd label view (Fig. 4-d).
 Figure 5: Two possible ways to apply crowd-made labels to the current label set in the label set refinement interface.
Figure 5: Two possible ways to apply crowd-made labels to the current label set in the label set refinement interface.
In DynamicLabels, we allow ML practitioners to make additions or replacements to their label set using crowd-made labels. The refinement actions can take place from refinement suggestions (Fig. 5-#1) or labels by each worker (Fig. 5-#2). On each refinement action, we display the action consequence modal (right of Fig. 5), where the change in the overview (the number of labels, coverage, conflict) is shown before making the change.
On the bottom left, there is a saved label sets component (Fig. 4-e), which enables exploration of potential candidates with version control.
 Figure 6: Overview of the study procedure containing tasks and procedure for each session.
Figure 6: Overview of the study procedure containing tasks and procedure for each session.
We conducted a 2-day study with 16 ML practitioners to investigate how DynamicLabels assists the ML label set construction process, through a within-subjects study comparing DynamicLabels to the baseline system, having annotation for crowd feedback and a table-like analysis for feedback review. Below are our results for each of the research questions.
Feedback from the crowd—–both annotation and crowd-made labels—contained diverse viewpoints and helped participants understand the various viewpoints of the crowd, some they had never expected before, and found it meaningful and useful in making refinements.
Both crowd annotations and crowd-made labels were utilized to help the participants understand and apply the feedback as refinements. The crowd annotations helped ML practitioners to (1) understand the crowd’s general opinions and perspectives and (2) spot the weakness of their label sets, and the crowd-made labels helped them (3) explore and apply relevant ones to their label sets.
Throughout the study, we were able to observe the distinctive benefits of DynamicLabels over the baseline system in making more informed refinement decisions. When asked to compare the two conditions on how they helped their refinement decisions, most participants (13/16) rated DynamicLabels better than baseline.
The results state that DynamicLabels supports (1) a high-level understanding of the feedback with metrics, (2) better assurance through examining multiple options, (3) a structured refinement process. In addition, DynamicLabels (4) encouraged a more flexible refinement and (5) surfaced issues that might have been missed in comparison to the baseline. Such benefits supported participants to make more confident, efficient refinements with crowd feedback.
Link to the ACM Digital Library
@inproceedings{10.1145/3640543.3645157,
author = {Park, Jeongeon and Ko, Eun-Young and Park, Yeon Su and Yim, Jinyeong and Kim, Juho},
title = {DynamicLabels: Supporting Informed Construction of Machine Learning Label Sets with Crowd Feedback},
year = {2024},
isbn = {9798400705083},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3640543.3645157},
doi = {10.1145/3640543.3645157},
abstract = {Label set construction—deciding on a group of distinct labels—is an essential stage in building a supervised machine learning (ML) application, as a badly designed label set negatively affects subsequent stages, such as training dataset construction, model training, and model deployment. Despite its significance, it is challenging for ML practitioners to come up with a well-defined label set, especially when no external references are available. Through our formative study (n=8), we observed that even with the help of external references or domain experts, ML practitioners still need to go through multiple iterations to gradually improve the label set. In this process, there exist challenges in collecting helpful feedback and utilizing it to make optimal refinement decisions. To support informed refinement, we present DynamicLabels, a system that aims to support a more informed label set-building process with crowd feedback. Crowd workers provide annotations and label suggestions to the ML practitioner’s label set, and the ML practitioner can review the feedback through multi-aspect analysis and refine the label set with crowd-made labels. Through a within-subjects study (n=16) using two datasets, we found that DynamicLabels enables better understanding and exploration of the collected feedback and supports a more structured and flexible refinement process. The crowd feedback helped ML practitioners explore diverse perspectives, spot current weaknesses, and shop from crowd-generated labels. Metrics and label suggestions in DynamicLabels helped in obtaining a high-level overview of the feedback, gaining assurance, and spotting surfacing conflicts and edge cases that could have been overlooked.},
booktitle = {Proceedings of the 29th International Conference on Intelligent User Interfaces},
pages = {209–228},
numpages = {20},
keywords = {artifact or system, crowdsourcing, label set construction, machine learning},
location = {, Greenville , SC , USA , },
series = {IUI '24}
}
![]()
![]()
This work was supported by NAVER CLOVA and the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No.2021-0- 01347, Video Interaction Technologies Using Object-Oriented Video Modeling).
